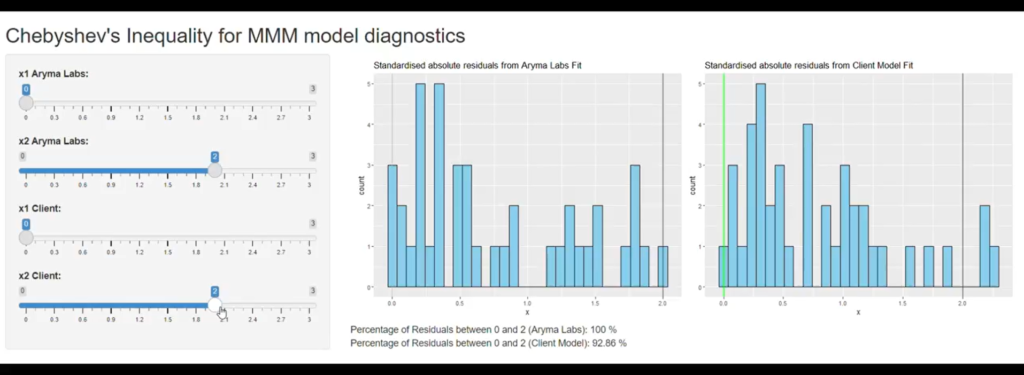
In MMM, You don’t need to train/test split your data.
Okay, some of you might be shocked since I am going against the conventional wisdom prevalent in ML circles.
But let me elaborate.
Ideally if your goal is inference, you don’t need to train/test split your data. In case of prediction, train/test split is justified as the model making such predictions is often black box-ish.
When the goal is inference, just as it is in case of Marketing Mix Modeling (MMM), train/test split means that your are ‘wasting data’.
The 25% or 30% data that could have been utilized for better specification of the model and thereby better understanding of data generating process is unnecessarily wasted to check the predictive power of the model.
MMM being a variant of Linear Regression is more about inference rather than prediction.
The fact that MMM could be used for prediction is just a positive side effect of having specified the model properly. The prediction is just a special case of retrodiction.
📌 How do we validate MMM model performance then?
I know that one of the ways to *prove* that MMM works much like any other ML model is to show the performance on unseen data aka ‘test data’.
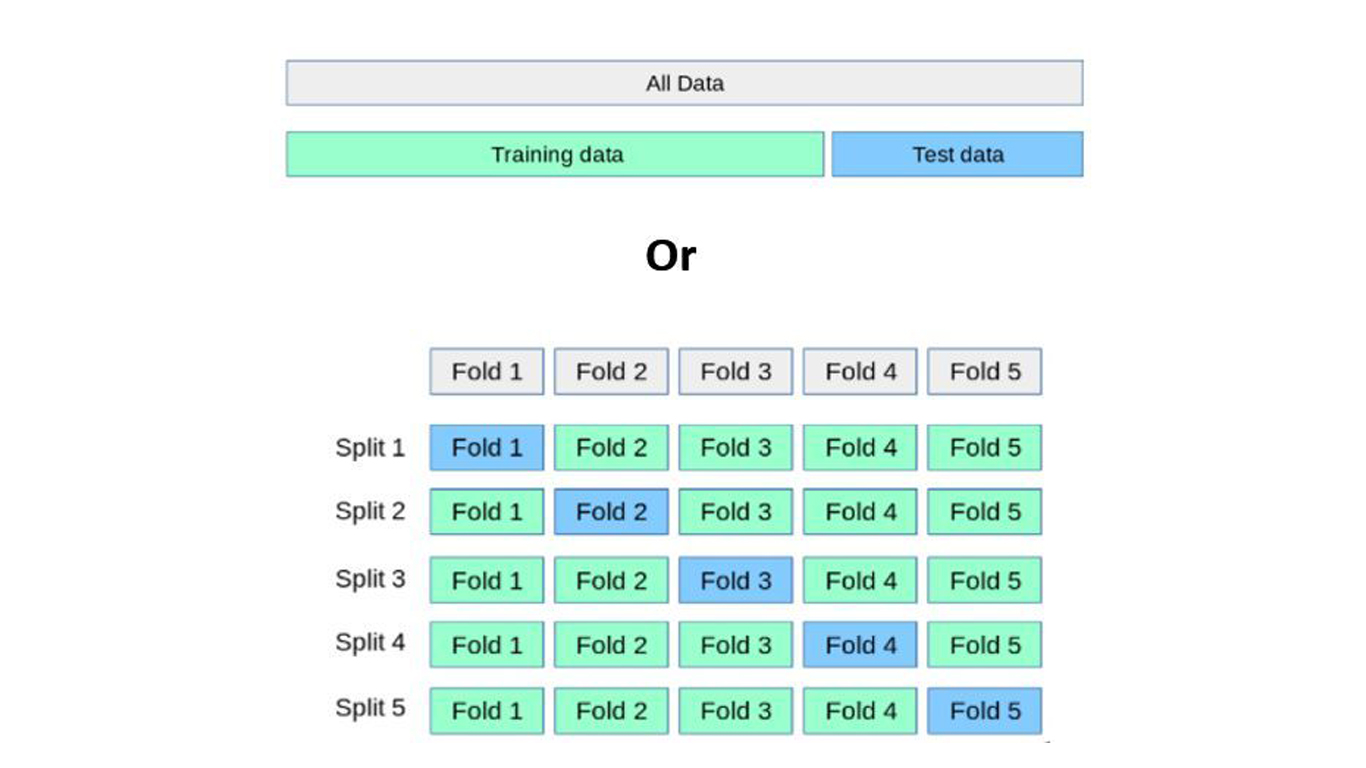
But to check the MMM’s performance, one could utilize Cross validation.
In an essence Cross Validation tests the model on the entire dataset although in subsequent sub samples or folds.
One kind of gets an ‘average’ measure of model consistency via CV.
Where as in Train-Test, not much can be known about model consistency merely based on one test set.
The only caveat wrt to CV in case of MMM is that one must be circumspect of the temporal effects. MMM has a temporal component and hence one should not shuffle the data haphazardly and perform CV.
This is akin to why one does not do shuffled CV in case of time series forecasting.
The right way to perform CV would be sequential, i.e. respecting the temporal aspect.
P.S The real test of any MMM is to implement it on the ground 😅